
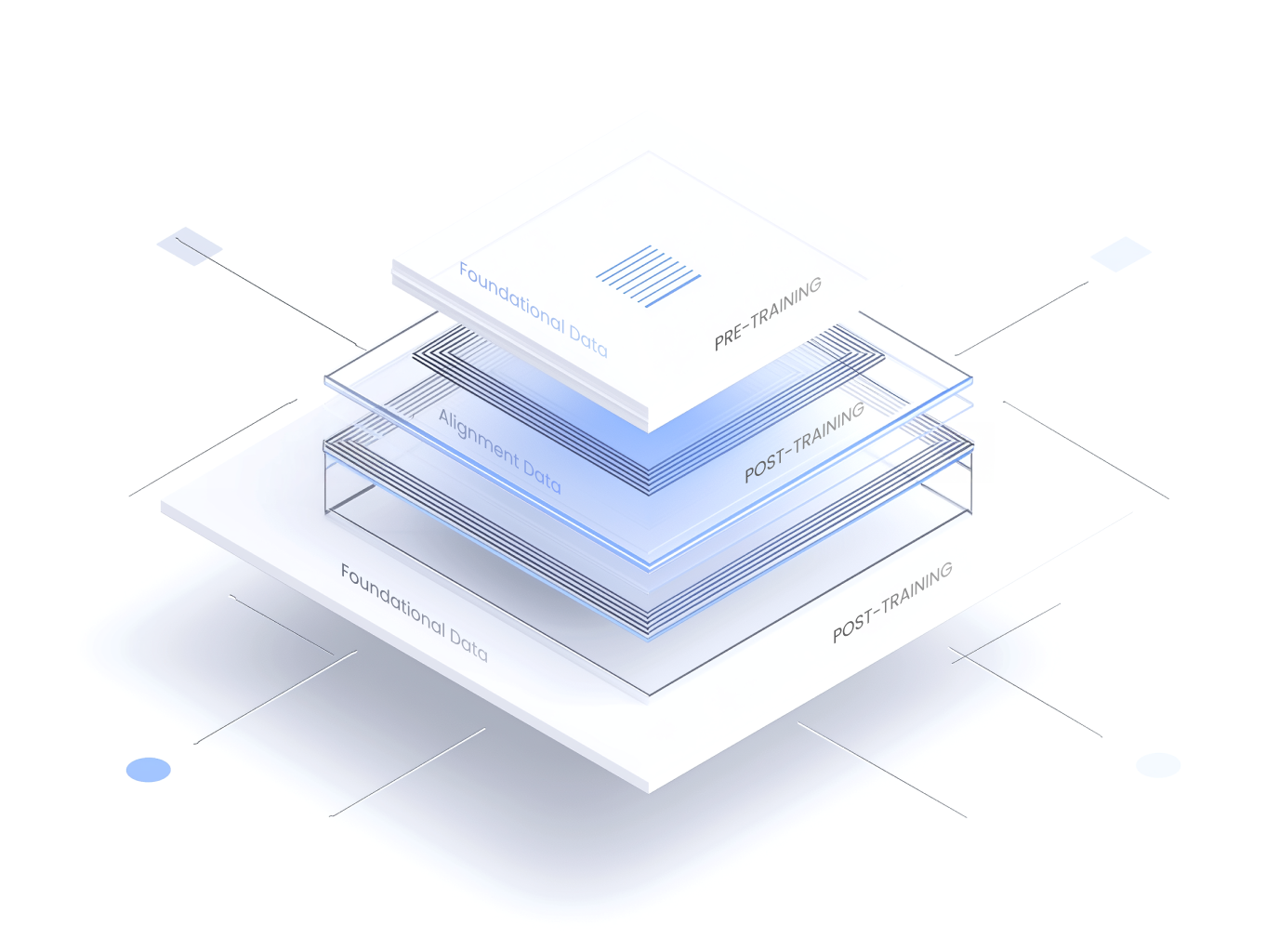
Foundational Data
Multilingual & multimodal text, speech, and image data built for foundational AI training.
Capturing the Real World Data AI has been Missing.
Multilingual & multimodal AI training data verified by human experts to maximize LLM performance. Continuously refined through a five-step quality pipeline, delivering 99.8% accuracy with 100% copyright-safe data.



Flitto powers AI development as a Multi-Phase, Multi-Modal, and Multi-Lingual platform — supporting every stage of the AI pipeline, seamlessly handling diverse data types including text, images, audio, and video, and enabling AI models to perform across languages and global markets.

'%3e%3cpath%20d='M21.5791%200C23.7853%200%2025.8868%201.27894%2027.4951%203.67676C29.1451%206.13862%2029.9993%209.19928%2030.0996%2012.3848L30.1104%2013.0234C30.1104%2014.4183%2029.9212%2015.5592%2029.582%2016.5186C29.4895%2016.7803%2029.3856%2017.0284%2029.2715%2017.2646C29.1954%2017.4222%2029.1144%2017.5743%2029.0293%2017.7217C28.3718%2018.8608%2027.0903%2019.9989%2024.9346%2019.999L24.6846%2019.9961C23.4451%2019.9596%2022.3246%2019.6308%2021.0938%2018.4697C20.0844%2017.519%2018.9039%2015.8298%2017.9961%2014.3115L15.2959%209.80078C15.2191%209.67249%2015.1404%209.54738%2015.0645%209.42285C14.988%209.5581%2014.9109%209.69486%2014.833%209.83301L13.8848%2011.5137C11.9791%2014.8926%2011.4958%2015.6625%2010.543%2016.9326C8.87294%2019.1565%207.4467%2019.999%205.56934%2019.999C3.34237%2019.999%201.93374%2019.0352%201.06152%2017.582C0.39402%2016.4718%200.0449463%2015.0363%200.00390625%2013.4023C0.0011728%2013.2935%203.34279e-06%2013.1838%200%2013.0732L0.0107422%2012.4678C0.113986%209.43657%200.988918%206.33484%202.56445%203.90527C2.7507%203.61821%202.94713%203.34184%203.15332%203.07812C4.18509%201.75846%205.45842%200.753676%206.88867%200.287109C7.0317%200.240457%207.17618%200.198747%207.32227%200.163086C7.76045%200.0561086%208.21212%203.47566e-05%208.6748%200C10.1041%200%2011.5251%200.423328%2013.0088%201.63477C13.7913%202.27336%2014.5977%203.11174%2015.4658%204.21094C16.1711%203.25801%2016.9305%202.35552%2017.749%201.6416C18.9594%200.58624%2020.2651%207.06586e-05%2021.5791%200ZM8.62305%203.27051C7.82022%203.27051%207.09288%203.62208%206.4375%204.22266C6.37182%204.28284%206.30643%204.34508%206.24219%204.41016C5.98565%204.67003%205.74074%204.96831%205.50684%205.29785C5.44843%205.38013%205.391%205.46467%205.33398%205.55078C4.04296%207.4994%203.25195%2010.4022%203.25195%2013.1895L3.26367%2013.6074C3.31647%2014.5539%203.54537%2015.2886%203.83398%2015.7559C4.26641%2016.4552%204.91183%2016.7509%205.56934%2016.751C6.41747%2016.751%207.19325%2016.5406%208.68848%2014.4727C9.88634%2012.8151%2011.2983%2010.4889%2012.248%209.03027L13.5264%207.06445C12.9013%206.17424%2012.3651%205.49574%2011.9785%205.08496C11.2047%204.26303%2010.2103%203.27058%208.62305%203.27051ZM21.4219%202.57715C19.8671%202.57735%2018.6161%203.74997%2017.21%205.84082C17.1213%205.97264%2017.0318%206.10755%2016.9424%206.24609C17.4434%206.98953%2017.9679%207.8155%2018.5195%208.73438L19.2939%2010.0244C21.1618%2013.1361%2022.2247%2014.7372%2022.8467%2015.4922C23.6467%2016.4618%2024.2068%2016.751%2024.9346%2016.751C26.7803%2016.7507%2027.2412%2015.0544%2027.2412%2013.1133C27.2411%2010.3471%2026.5955%207.27751%2025.1748%205.08398C24.1665%203.52802%2022.8595%202.57715%2021.4219%202.57715Z'%20fill='%231A1A1A'%20fill-opacity='0.57'/%3e%3cpath%20d='M36.4326%200.631836H40.1948L46.5914%2012.2042L52.9891%200.631836H56.6696V19.6469H53.6006V5.07356L47.9903%2015.1654H45.1108L39.5016%205.07356V19.6469H36.4326V0.631836ZM66.286%207.72164C64.085%207.72164%2062.7594%209.37812%2062.4422%2011.4294H69.9121C69.7581%209.31635%2068.5393%207.72164%2066.286%207.72164ZM59.3993%2012.5979C59.3993%208.28183%2062.1888%205.14058%2066.3394%205.14058C70.422%205.14058%2072.8596%208.24204%2072.8596%2012.8283V13.6712H62.4422C62.8118%2015.9025%2064.2924%2017.4061%2066.6797%2017.4061C68.5844%2017.4061%2069.7749%2016.825%2070.9037%2015.7622L72.534%2017.759C70.9979%2019.1715%2069.044%2019.9861%2066.5708%2019.9861C62.0778%2019.9861%2059.3993%2016.7098%2059.3993%2012.5979ZM76.5809%207.99388H73.7559V5.48088H76.5809V1.32501H79.5421V5.48088H83.8341V7.99388H79.5421V14.3633C79.5421%2016.5381%2080.2374%2017.3108%2081.9462%2017.3108C82.7263%2017.3108%2083.1734%2017.2438%2083.8341%2017.1339V19.6196C83.0111%2019.8521%2082.2258%2019.9589%2081.3755%2019.9589C78.1788%2019.9589%2076.5809%2018.2124%2076.5809%2014.7162V7.99388ZM96.3027%2010.4378C95.708%208.93625%2094.3814%207.83053%2092.4317%207.83053C89.8977%207.83053%2088.2758%209.62838%2088.2758%2012.5571C88.2758%2015.4125%2089.769%2017.2972%2092.3102%2017.2972C94.3081%2017.2972%2095.7342%2016.135%2096.3027%2014.6889V10.4378ZM99.2639%2019.6469H96.3572V17.6637C95.5447%2018.8312%2094.0662%2019.9861%2091.6715%2019.9861C87.8203%2019.9861%2085.2466%2016.7622%2085.2466%2012.5571C85.2466%208.31219%2087.8821%205.14058%2091.8348%205.14058C93.7887%205.14058%2095.3216%205.9217%2096.3572%207.30071V5.48088H99.2639V19.6469Z'%20fill='%231A1A1A'%20fill-opacity='0.57'/%3e%3c/g%3e%3c/svg%3e)








From Pre-Training Data to Post-Training Data
Multilingual & multimodal text, speech, and image data built for foundational AI training.

RLHF, multi-turn dialogue, and safety data aligned to human intent and values.

State-of-the-art benchmark, CoT, and coding datasets designed to push the limits of frontier AI models.
Flitto collaborates with experts across diverse fields to build and collect AI training data, showcasing both completed and ongoing projects.
Medical domain expertise, Experience in voice recording dataset development
About the role
Voice data covering real-world medical consultation flows, from initial symptom descriptions to department matching and in-depth medical interviews.
MoreMedical domain expertise, Experience in voice recording dataset development
About the role
Voice and text data built from native-speaker recordings of medical terminology used in clinical settings, including disease names, medication names, and test names, paired with accurate transcriptions.
MoreMedical billing domain expertise, Experience in voice recording dataset development
About the role
Korean multi-turn voice data based on real hospital billing workflows, including medical bill payments, insurance coverage inquiries, and receipt issuance.
MoreFrom global AI enterprises to national AI initiatives, we build long-term partnerships grounded in trust.
An exceptional partner, truly quality-centered and detail-oriented.
Flitto is a partner genuinely committed to quality and attention to detail. Their proactive approach in identifying issues we hadn’t even considered significantly improved our internal collaboration and overall project quality."
Senior Manager, Global Tech Giant
Flitto delivered specialized data no other vendor could source — fast.
What impressed us most about Flitto was how quickly they understood not only the project requirements, but also the broader goals behind them. The data consistently met a high standard in evaluations by our model team, and when we needed highly specialized data that other vendors couldn’t source, Flitto delivered quickly."
Director of Engineering, Top-Tier Tech Enterprise
Yes. Flitto provides AI training data samples tailored to your model, domain, and language requirements, allowing your team to validate quality before committing. Samples are available for LLM training, RLHF, speech datasets, and multimodal datasets.
Every AI training dataset goes through a five-step QC pipeline combining expert human review and AI-assisted validation. Annotation accuracy is human-verified to 99.8% across all languages and modalities, ensuring production-ready quality for LLM training and RLHF workflows.
AI data platforms such as Scale AI and Mercor have helped shape the modern AI training data ecosystem by enabling teams to source, label, and evaluate large-scale datasets for model development. Flitto operates in the same category, with a distinct focus on human-verified language data built from real-world multilingual interactions. We specialize in multilingual parallel corpora, low-resource language data, and multimodal datasets that capture linguistic nuance and cultural context beyond conventional data pipelines. These capabilities are powered by a global crowd platform of 14 million users across 173 countries, a five-step QC pipeline with 99.8% accuracy, and more than a decade of experience spanning RLHF, speech, OCR, and multimodal data.
A custom AI dataset is built to match the requirements of a specific model or use case, including language, domain, modality, and task type. At Flitto, custom datasets go beyond specification design. We deliver them through a fast, scalable end-to-end workflow tailored to your requirements. Based on your project goals, we design a data collection strategy and leverage our global platform of millions of users to rapidly gather data at scale. Each dataset is refined through human-in-the-loop validation and continuously improved through client feedback.
Pricing is determined based on factors such as data type, volume, language coverage, and level of customization. Flitto provides transparent, project-based pricing tailored to your requirements. Once we receive your request, our team reviews the project scope and delivers a clear quotation within 48 hours, depending on the dataset’s complexity and scale.
Flitto supports a wide range of industries, including finance, manufacturing, legal, healthcare, IT, and e-commerce, delivering domain-specific datasets optimized for real-world AI applications. Our datasets extend beyond traditional text data, with a strong focus on multimodal AI training data. This includes large-scale speech datasets, OCR and vision-based image data, multi-turn conversational datasets, and human-feedback-driven datasets such as RLHF and instruction tuning data. We also provide workflow-oriented datasets designed for advanced AI systems, supporting use cases such as speech recognition, conversational AI, multimodal understanding, and next-generation agentic AI.
From ready-to-use AI training data to high-quality custom datasets, consult with our experts to find the right data for your AI models.